
![]()
[May 22, 2024] Valid Databricks-Certified-Data-Engineer-Associate Test Answers & Databricks-Certified-Data-Engineer-Associate Exam PDF
Valid Databricks Certification Databricks-Certified-Data-Engineer-Associate Dumps Ensure Your Passing
The Databricks Databricks-Certified-Data-Engineer-Associate exam is conducted online and consists of 80 multiple-choice questions. The duration of the exam is 2 hours, and candidates must achieve a minimum score of 60% to pass. Databricks-Certified-Data-Engineer-Associate exam fee is $300, and candidates can schedule their exam at any time through the GAQM website. Databricks Certified Data Engineer Associate Exam certification is valid for three years and can be renewed by passing the latest version of the exam.
Databricks Certified Data Engineer Associate certification exam covers topics such as data engineering concepts, data ingestion, data processing, data storage, and data transformation using Apache Spark and Delta Lake. Candidates who pass Databricks-Certified-Data-Engineer-Associate exam will have a deep understanding of the Databricks platform and will be able to design, build, and maintain data pipelines that are scalable, reliable, and efficient. Databricks Certified Data Engineer Associate Exam certification is ideal for data engineers, data analysts, and data scientists who work with big data and want to enhance their skills and advance their careers.
NEW QUESTION # 11
A data analyst has developed a query that runs against Delta table. They want help from the data engineering team to implement a series of tests to ensure the data returned by the query is clean. However, the data engineering team uses Python for its tests rather than SQL.
Which of the following operations could the data engineering team use to run the query and operate with the results in PySpark?
- A. There is no way to share data between PySpark and SQL.
- B. SELECT * FROM sales
- C. spark.sql
- D. spark.delta.table
- E. spark.table
Answer: C
Explanation:
Explanation
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.sql("SELECT * FROM sales")
print(df.count())
NEW QUESTION # 12
A data engineer has created a new database using the following command:
CREATE DATABASE IF NOT EXISTS customer360;
In which of the following locations will the customer360 database be located?
- A. dbfs:/user/hive/customer360
- B. dbfs:/user/hive/database/customer360
- C. dbfs:/user/hive/warehouse
- D. More information is needed to determine the correct response
Answer: C
Explanation:
Explanation
dbfs:/user/hive/warehouse - which is the default location
NEW QUESTION # 13
Which of the following is stored in the Databricks customer's cloud account?
- A. Databricks web application
- B. Data
- C. Repos
- D. Cluster management metadata
- E. Notebooks
Answer: B
Explanation:
The only option that is stored in the Databricks customer's cloud account is data. Data is stored in the customer's cloud storage service, such as AWS S3 or Azure Data Lake Storage. The customer has full control and ownership of their data and can access it directly from their cloud account.
Option A is not correct, as the Databricks web application is hosted and managed by Databricks on their own cloud infrastructure. The customer does not need to install or maintain the web application, but only needs to access it through a web browser.
Option B is not correct, as the cluster management metadata is stored and managed by Databricks on their own cloud infrastructure. The cluster management metadata includes information such as cluster configuration, status, logs, and metrics. The customer can view and manage their clusters through the Databricks web application, but does not have direct access to the cluster management metadata.
Option C is not correct, as the repos are stored and managed by Databricks on their own cloud infrastructure.
Repos are version-controlled repositories that store code and data files for Databricks projects. The customer can create and manage their repos through the Databricks web application, but does not have direct access to the repos.
Option E is not correct, as the notebooks are stored and managed by Databricks on their own cloud infrastructure. Notebooks are interactive documents that contain code, text, and visualizations for Databricks workflows. The customer can create and manage their notebooks through the Databricks web application, but does not have direct access to the notebooks.
References:
* Databricks Architecture
* Databricks Data Sources
* Databricks Repos
* [Databricks Notebooks]
* [Databricks Data Engineer Professional Exam Guide]
NEW QUESTION # 14
A data engineer has configured a Structured Streaming job to read from a table, manipulate the data, and then perform a streaming write into a new table.
The code block used by the data engineer is below:
If the data engineer only wants the query to process all of the available data in as many batches as required, which of the following lines of code should the data engineer use to fill in the blank?
- A. trigger(availableNow=True)
- B. trigger(continuous="once")
- C. trigger(parallelBatch=True)
- D. trigger(processingTime="once")
- E. processingTime(1)
Answer: A
Explanation:
https://spark.apache.org/docs/latest/api/python/reference/pyspark.ss/api/pyspark.sql.streaming.DataStreamWriter
NEW QUESTION # 15
A data engineer is working with two tables. Each of these tables is displayed below in its entirety.
The data engineer runs the following query to join these tables together:
Which of the following will be returned by the above query?
- A. Option E
- B. Option D
- C. Option C
- D. Option B
- E. Option A
Answer: E
Explanation:
Option A is the correct answer because it shows the result of an INNER JOIN between the two tables. An INNER JOIN returns only the rows that have matching values in both tables based on the join condition. In this case, the join condition is ON a.customer_id = c.customer_id, which means that only the rows that have the same customer ID in both tables will be included in the output. The output will have four columns:
customer_id, name, account_id, and overdraft_amt. The output will have four rows, corresponding to the four customers who have accounts in the account table.
References: The use of INNER JOIN can be referenced from Databricks documentation on SQL JOIN or from other sources like W3Schools or GeeksforGeeks.
NEW QUESTION # 16
A data engineer has been using a Databricks SQL dashboard to monitor the cleanliness of the input data to an ELT job. The ELT job has its Databricks SQL query that returns the number of input records containing unexpected NULL values. The data engineer wants their entire team to be notified via a messaging webhook whenever this value reaches 100.
Which of the following approaches can the data engineer use to notify their entire team via a messaging webhook whenever the number of NULL values reaches 100?
- A. They can set up an Alert with a new email alert destination.
- B. They can set up an Alert with one-time notifications.
- C. They can set up an Alert without notifications.
- D. They can set up an Alert with a new webhook alert destination.
- E. They can set up an Alert with a custom template.
Answer: D
Explanation:
A webhook alert destination is a way to send notifications to external applications or services via HTTP requests. A data engineer can use a webhook alert destination to notify their entire team via a messaging webhook, such as Slack or Microsoft Teams, whenever the number of NULL values in the input data reaches
100. To set up a webhook alert destination, the data engineer needs to do the following steps:
* In the Databricks SQL workspace, navigate to the Settings gear icon and select SQL Admin Console.
* Click Alert Destinations and click Add New Alert Destination.
* Select Webhook and enter the webhook URL and the optional custom template for the notification message.
* Click Create to save the webhook alert destination.
* In the Databricks SQL editor, create or open the query that returns the number of input records containing unexpected NULL values.
* Click the Create Alert icon above the editor window and configure the alert criteria, such as the value column, the condition, and the threshold.
* In the Notification section, select the webhook alert destination that was created earlier and click Create Alert. References: What are Databricks SQL alerts?, Monitor alerts, Monitoring Your Business with
* Alerts, Using Automation Runbook Webhooks To Alert on Databricks Status Updates.
NEW QUESTION # 17
A data organization leader is upset about the data analysis team's reports being different from the data engineering team's reports. The leader believes the siloed nature of their organization's data engineering and data analysis architectures is to blame.
Which of the following describes how a data lakehouse could alleviate this issue?
- A. Both teams would use the same source of truth for their work
- B. Both teams would be able to collaborate on projects in real-time
- C. Both teams would autoscale their work as data size evolves
- D. Both teams would respond more quickly to ad-hoc requests
- E. Both teams would reorganize to report to the same department
Answer: A
Explanation:
A data lakehouse is a data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data12. By using a data lakehouse, both the data analysis and data engineering teams can access the same data sources and formats, ensuring data consistency and quality across their reports. A data lakehouse also supports schema enforcement and evolution, data validation, and time travel to old table versions, which can help resolve data conflicts and errors1. References: 1: What is a Data Lakehouse? - Databricks 2: What is a data lakehouse? | IBM
NEW QUESTION # 18
Which of the following commands will return the location of database customer360?
- A. USE DATABASE customer360;
- B. DROP DATABASE customer360;
- C. ALTER DATABASE customer360 SET DBPROPERTIES ('location' = '/user'};
- D. DESCRIBE DATABASE customer360;
- E. DESCRIBE LOCATION customer360;
Answer: D
Explanation:
The command DESCRIBE DATABASE customer360; will return the location of the database customer360, along with its comment and properties. This command is an alias for DESCRIBE SCHEMA customer360;, which can also be used to get the same information. The other commands will either drop the database, alter its properties, or use it as the current database, but will not return its location12. References:
* DESCRIBE DATABASE | Databricks on AWS
* DESCRIBE DATABASE - Azure Databricks - Databricks SQL
NEW QUESTION # 19
A data engineer and data analyst are working together on a data pipeline. The data engineer is working on the raw, bronze, and silver layers of the pipeline using Python, and the data analyst is working on the gold layer of the pipeline using SQL. The raw source of the pipeline is a streaming input. They now want to migrate their pipeline to use Delta Live Tables.
Which of the following changes will need to be made to the pipeline when migrating to Delta Live Tables?
- A. The pipeline will need to be written entirely in SQL
- B. None of these changes will need to be made
- C. The pipeline will need to stop using the medallion-based multi-hop architecture
- D. The pipeline will need to be written entirely in Python
- E. The pipeline will need to use a batch source in place of a streaming source
Answer: B
NEW QUESTION # 20
A data analyst has a series of queries in a SQL program. The data analyst wants this program to run every day.
They only want the final query in the program to run on Sundays. They ask for help from the data engineering team to complete this task.
Which of the following approaches could be used by the data engineering team to complete this task?
- A. They could submit a feature request with Databricks to add this functionality.
- B. They could redesign the data model to separate the data used in the final query into a new table.
- C. They could automatically restrict access to the source table in the final query so that it is only accessible on Sundays.
- D. They could wrap the queries using PySpark and use Python's control flow system to determine when to run the final query.
- E. They could only run the entire program on Sundays.
Answer: D
NEW QUESTION # 21
A data engineering team has noticed that their Databricks SQL queries are running too slowly when they are submitted to a non-running SQL endpoint. The data engineering team wants this issue to be resolved.
Which of the following approaches can the team use to reduce the time it takes to return results in this scenario?
- A. They can turn on the Serverless feature for the SQL endpoint and change the Spot Instance Policy to
"Reliability Optimized." - B. They can increase the maximum bound of the SQL endpoint's scaling range
- C. They can turn on the Serverless feature for the SQL endpoint.
- D. They can increase the cluster size of the SQL endpoint.
- E. They can turn on the Auto Stop feature for the SQL endpoint.
Answer: C
Explanation:
Explanation
Databricks SQL endpoints can run in two modes: Serverless and Dedicated. Serverless mode allows you to run queries without managing clusters, while Dedicated mode allows you to run queries on a specific cluster.
Serverless mode is faster and more cost-effective for ad-hoc queries, especially when the SQL endpoint is not running. Dedicated mode is more suitable for predictable and consistent performance, especially for long-running queries. By turning on the Serverless feature for the SQL endpoint, the data engineering team can reduce the time it takes to start the SQL endpoint and return results. The other options are not relevant or effective for this scenario. References: Databricks SQL endpoints, New Performance Improvements in Databricks SQL, Slowness when fetching results in Databricks SQL
NEW QUESTION # 22
A data engineer runs a statement every day to copy the previous day's sales into the table transactions. Each day's sales are in their own file in the location "/transactions/raw".
Today, the data engineer runs the following command to complete this task:
After running the command today, the data engineer notices that the number of records in table transactions has not changed.
Which of the following describes why the statement might not have copied any new records into the table?
- A. The names of the files to be copied were not included with the FILES keyword.
- B. The previous day's file has already been copied into the table.
- C. The PARQUET file format does not support COPY INTO.
- D. The format of the files to be copied were not included with the FORMAT_OPTIONS keyword.
- E. The COPY INTO statement requires the table to be refreshed to view the copied rows.
Answer: B
NEW QUESTION # 23
A data engineer has left the organization. The data team needs to transfer ownership of the data engineer's Delta tables to a new data engineer. The new data engineer is the lead engineer on the data team.
Assuming the original data engineer no longer has access, which of the following individuals must be the one to transfer ownership of the Delta tables in Data Explorer?
- A. This transfer is not possible
- B. Original data engineer
- C. Workspace administrator
- D. Databricks account representative
- E. New lead data engineer
Answer: E
NEW QUESTION # 24
A data engineer has been using a Databricks SQL dashboard to monitor the cleanliness of the input data to an ELT job. The ELT job has its Databricks SQL query that returns the number of input records containing unexpected NULL values. The data engineer wants their entire team to be notified via a messaging webhook whenever this value reaches 100.
Which of the following approaches can the data engineer use to notify their entire team via a messaging webhook whenever the number of NULL values reaches 100?
- A. They can set up an Alert with a new email alert destination.
- B. They can set up an Alert with one-time notifications.
- C. They can set up an Alert without notifications.
- D. They can set up an Alert with a new webhook alert destination.
- E. They can set up an Alert with a custom template.
Answer: D
NEW QUESTION # 25
A dataset has been defined using Delta Live Tables and includes an expectations clause:
CONSTRAINT valid_timestamp EXPECT (timestamp > '2020-01-01') ON VIOLATION DROP ROW What is the expected behavior when a batch of data containing data that violates these constraints is processed?
- A. Records that violate the expectation are dropped from the target dataset and loaded into a quarantine table.
- B. Records that violate the expectation are added to the target dataset and flagged as invalid in a field added to the target dataset.
- C. Records that violate the expectation are added to the target dataset and recorded as invalid in the event log.
- D. Records that violate the expectation are dropped from the target dataset and recorded as invalid in the event log.
- E. Records that violate the expectation cause the job to fail.
Answer: C
NEW QUESTION # 26
Which of the following commands can be used to write data into a Delta table while avoiding the writing of duplicate records?
- A. DROP
- B. INSERT
- C. APPEND
- D. IGNORE
- E. MERGE
Answer: E
Explanation:
The MERGE command can be used to upsert data from a source table, view, or DataFrame into a target Delta table. It allows you to specify conditions for matching and updating existing records, and inserting new records when no match is found. This way, you can avoid writing duplicate records into a Delta table1. The other commands (DROP, IGNORE, APPEND, INSERT) do not have this functionality and may result in duplicate records or data loss234. References: 1: Upsert into a Delta Lake table using merge | Databricks on AWS 2: SQL DELETE | Databricks on AWS 3: SQL INSERT INTO | Databricks on AWS 4: SQL UPDATE | Databricks on AWS
NEW QUESTION # 27
A data engineer that is new to using Python needs to create a Python function to add two integers together and return the sum?
Which of the following code blocks can the data engineer use to complete this task?
- A.

- B.
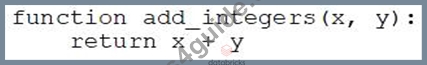
- C.

- D.

- E.

Answer: C
Explanation:
Explanation
https://www.w3schools.com/python/python_functions.asp
NEW QUESTION # 28
A data engineer is designing a data pipeline. The source system generates files in a shared directory that is also used by other processes. As a result, the files should be kept as is and will accumulate in the directory. The data engineer needs to identify which files are new since the previous run in the pipeline, and set up the pipeline to only ingest those new files with each run.
Which of the following tools can the data engineer use to solve this problem?
- A. Databricks SQL
- B. Delta Lake
- C. Auto Loader
- D. Data Explorer
- E. Unity Catalog
Answer: C
Explanation:
Explanation
Auto Loader incrementally and efficiently processes new data files as they arrive in cloud storage without any additional setup.https://docs.databricks.com/en/ingestion/auto-loader/index.html
NEW QUESTION # 29
Which of the following is hosted completely in the control plane of the classic Databricks architecture?
- A. Databricks web application
- B. Driver node
- C. JDBC data source
- D. Worker node
- E. Databricks Filesystem
Answer: A
Explanation:
The Databricks web application is the user interface that allows you to create and manage workspaces, clusters, notebooks, jobs, and other resources. It is hosted completely in the control plane of the classic Databricks architecture, which includes the backend services that Databricks manages in your Databricks account. The other options are part of the compute plane, which is where your data is processed by compute resources such as clusters. The compute plane is in your own cloud account and network.
References: Databricks architecture overview, Security and Trust Center
NEW QUESTION # 30
......
The GAQM Databricks-Certified-Data-Engineer-Associate (Databricks Certified Data Engineer Associate) Certification Exam is designed to test the skills of data engineers who work with Databricks to build and maintain data pipelines. Databricks-Certified-Data-Engineer-Associate exam covers a wide range of topics, including data modeling, data ingestion, data transformation, and data analysis. Successful completion of the exam demonstrates that a candidate has the skills and knowledge required to work effectively as a data engineer with Databricks.
Databricks-Certified-Data-Engineer-Associate Dumps Real Exam Questions Test Engine Dumps Training: https://www.pass4guide.com/Databricks-Certified-Data-Engineer-Associate-exam-guide-torrent.html
Databricks-Certified-Data-Engineer-Associate exam dumps and online Test Engine: https://drive.google.com/open?id=1_5BRJSQdgwAmGAVz9Ep-ceVrN0I_veKb